Non-technical readers: the first sections are for you. Technically curious: the appendix is the machine room.
Two small icons run through this: 🧳 is the travel example, 🛠️ is the work example. Same machine, two very different jobs. The occasional 🔍 is an optional aside for the curious, skip it and you lose nothing.

The one-liner
I built a second brain. It’s a folder of plain text files that an AI reads, writes, links, and keeps tidy for me. I feed it what I read, watch, and think. It hands me back a version of my own mind that doesn’t forget. As of today:
- more than 60 interlinked wiki articles, written by the AI from my sources
- 272 raw source notes (articles, videos, podcasts, books)
- 524 pieces of generated work (research, travel guides, plans)
- 330 weekly reflections on my own life, going back to 2019
- a live memory layer running on a server, so every conversation builds on the last
Where it came from
I’m getting older, and I could feel it. I was consuming an enormous amount, articles, talks, books, ideas, and keeping almost none of it. The thing that changed my mind last year, gone. The insight I had on a long walk, re-figured-out months later because I couldn’t find where I’d worked it out. That’s a quietly horrifying feeling: that your own thinking is leaking out as fast as it comes in.
So I built something to catch it. In early 2025 it was a tiny tool: paste a YouTube or web link, and an AI turns it into a clean note I’d never lose. And even then it wasn’t a generic summary. It was written for me, filtered through a profile of what I care about and how I think, so the note came back in my own terms, keeping the parts I’d actually want and sounding like me. That was the first path. The need to not forget what I take in.
But there was a second path, and it’s older and longer. Since 2019 I’ve written a reflection every single week about my own life: what I learned, what I got wrong, what I’m becoming. More than 330 of them now. That’s a different kind of memory. Not what I consumed, but what I lived. For years those two things sat in separate worlds: a growing pile of notes about the world’s ideas, and a long private journal about mine.
The real breakthrough was realizing they’re the same problem, and merging them. One system that remembers both what I take in and what I work out, and connects the two. That merge is what turned a note-taking tool into a second brain.
And somewhere in there it flipped. Over 9 months the little tool kept outgrowing itself: it learned to transcribe podcasts, to remember what I’d saved, to discover new things, to learn how I think. At some point I realized I’d built an app I had to operate, when what I wanted was a system that operates for me. So I rebuilt it from scratch as the thing you’re about to see. That’s the one sentence to hold onto: it went from an app I operated to a system that operates for me.
Enough backstory. Here’s what it actually does.
The one picture to hold
Picture a private research library. The shelves are yours. Every book, every note, every clipping you’ve ever cared about, all in one place, and you could walk in and read any of it yourself.
Now picture a brilliant, tireless librarian who lives in that library. You hand them anything: a video, an article, a messy thought. They read it, file it, write a clean summary card, and cross-reference it to everything else you’ve ever brought in, including shelves you’d never have thought to connect. Ask them a question and they pull the answer in seconds, in your own words, from your own collection. Walk in tomorrow and they remember every conversation you’ve had.

That librarian isn’t a person. It’s the AI. And here’s the design choice that sounds strange until it clicks: the whole library is organized for how the librarian works best, not for how it looks to a visitor. Roughly 80 percent of it is built for the machine. I get a better library precisely because I stopped optimizing it for human browsing and optimized it for the thing that does the work.
(Yes, I know. A Zettelkasten with a brain bolted on. Every German nerd’s destiny, apparently.)
What it actually does
Here’s the librarian’s job, broken into the things it does for me. Two running examples so you see it’s not a one-trick thing: 🧳 a trip, and 🛠️ my actual work.
It ingests anything, in my terms. Drop in an article, a YouTube link, a podcast, a PDF, a book, and it turns the raw thing into a clean, structured note. Not a generic summary, a note shaped to my profile, keeping what matters to me and written the way I’d write it. No copy-paste, no manual summarizing.
It writes its own encyclopedia. This is the magic part. It doesn’t just store notes, it compiles them. Ten notes on the same topic get braided into one coherent article, cross-linked to related articles, like a personal Wikipedia that writes and maintains itself. 🛠️ My article on AI engineering grew from 49 to 64 sources in a single week, because every work session I do feeds back into it automatically. It gets more complete while I sleep.
It answers from my own mind. I can ask it a question and it answers from everything I’ve accumulated, in my voice, not generic internet advice. It’s the difference between asking a search engine and asking a version of yourself that actually remembers everything you’ve ever learned.
It does real travel research. 🧳 Planning Chiang Mai, I don’t want the same ten tourist traps every blog lists. So it doesn’t take one path, it takes several at once: it searches in the local language, queries the map data directly through an API, and deliberately thinks around the corner, um die Ecke, hunting the vocabulary that real specialty places actually use. That surfaces genuine local gems, highly rated but under the radar, and then, crucially, it checks that each one is still open and still itself. Blogs and aggregators keep dead cafés alive for months. A small program confirms the place is real and operating before it ever reaches my list.
It finds new things without trapping me in a bubble. It watches sources I trust and matches new content to a profile of what I care about, but it deliberately mixes in surprise picks that challenge me, so it stays a window, not a mirror.
It remembers my work, not just my reading. Every time I finish a working session with the AI, it summarizes what we did and files it back into the library. So my own work compounds too. More than 550 of my recent sessions got automatically analyzed into reusable patterns.
It digests my past, not just my present. 🛠️ Right now it’s working through about 1,600 files from 8 years of consulting, old client projects, decisions, playbooks scattered across Google Drive, and distilling them into structured, queryable craft. A decade of messy folders is becoming a clean body of knowledge I can actually ask questions of.
It writes in my voice. The system holds a guide to how I actually write, so when it drafts something it sounds like me, not like generic AI. It even knows I have two voices: a raw, personal, reflective one, and a sculpted essay voice for things I publish. It picks the right one for the moment. (This piece was drafted in the second one.)
It’s with me everywhere. The whole library syncs across my laptop, my phone, and the server. I can reach my entire second brain from my phone on a beach. 🧳 Months after that Chiang Mai trip, I can stand somewhere and ask “what was that café I loved?” and it remembers, because the trip got compiled into a guide and the memory layer kept it.
It’s a mirror for thinking. This is the quiet one, and the part I’m most careful with. This is where those weekly reflections come back in. Because the library holds years of my own thinking and remembers across time, it can notice patterns I can’t see myself: a worry that keeps recurring across years, a value that’s been quietly shifting. It’s become a place where I think honestly, with no audience, about my own life and growth. None of that content is in this document and it never will be. But the depth is there, and it’s a kind of clarity that’s hard to get any other way. It’s a thinking partner, not a replacement for the real people I think with.

And all of it compounds. This is the loop that makes the whole thing more than the sum of its parts. Every input makes the next answer better. The wiki grows, the memory deepens, the profile sharpens. A normal notes app is the same on day 1,000 as on day 1. This gets smarter the longer I use it.
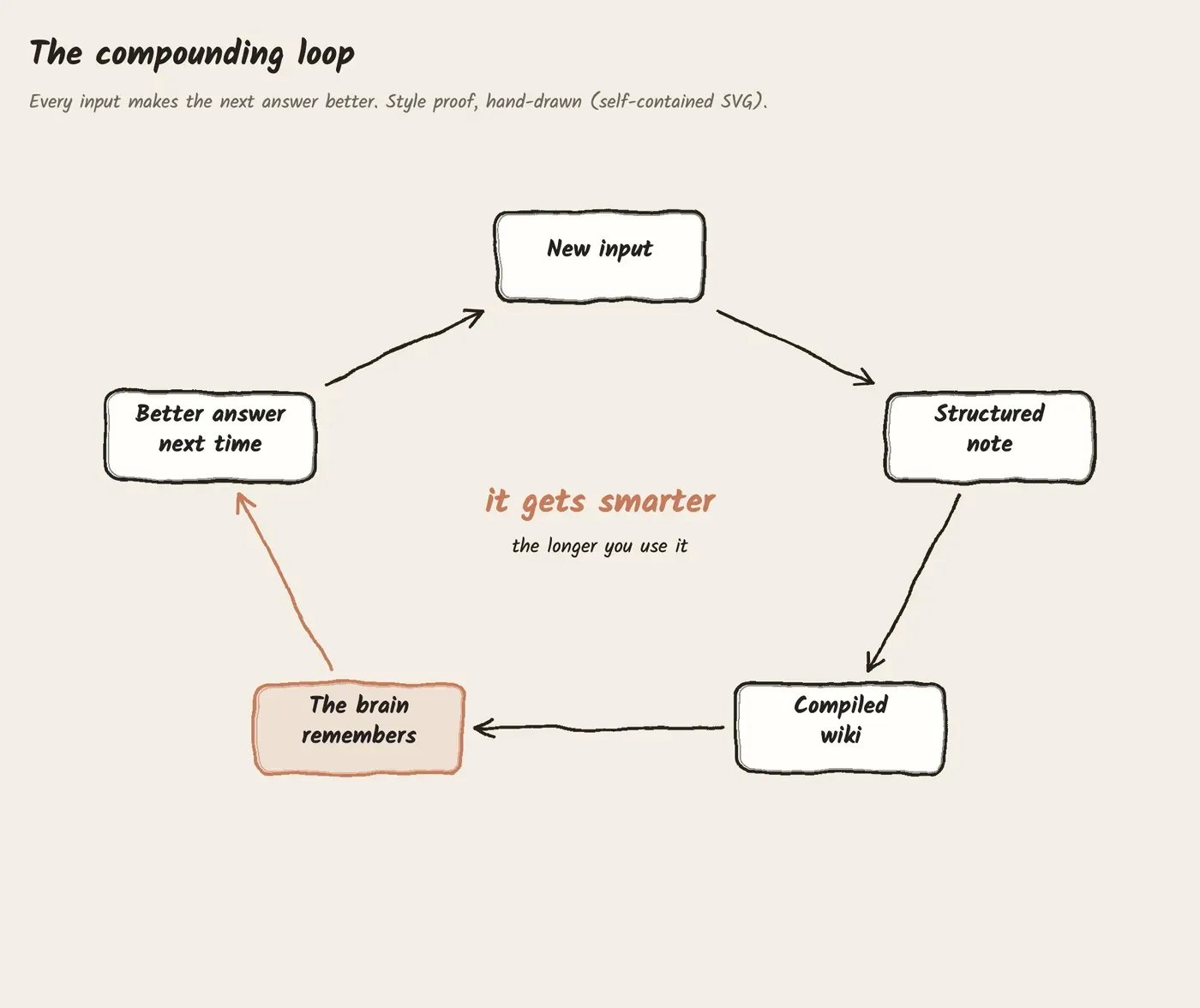
🔍 Go deeper: “compile” means the AI reads many of my raw notes on one topic and writes a single synthesized article from them, with links to related articles, then updates it as new notes arrive. It’s not copy-paste, it’s synthesis.
How it works, gently
You don’t need any of this to use it, but here’s the shape, because three ideas explain almost everything.
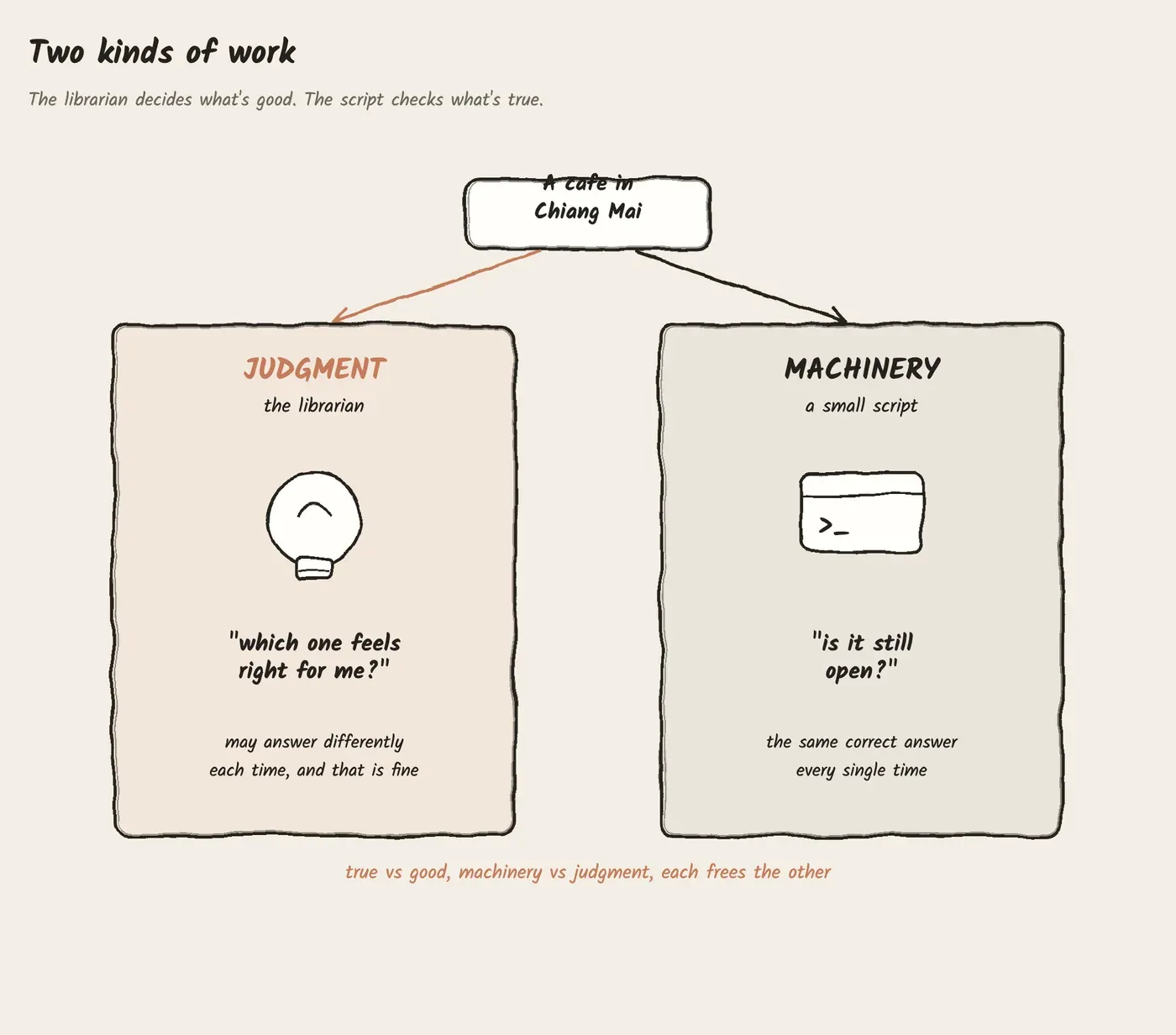
Two kinds of work: judgment and machinery. The AI is brilliant at judgment: reasoning, writing, connecting ideas, reading nuance. But ask it the same factual question twice and you might get two slightly different answers. That’s fine for thinking, dangerous for facts. So for anything that has to be exact and repeatable, is this café still open, what are the real gems in this city, pull this video’s exact transcript, I wrote small programs instead. A program gives the same correct answer every single time, for basically zero cost. 16 of these little programs do the precise, repeatable work, and the AI does the thinking. Each one frees the other to do what it’s good at. 🧳 The “is this café still open” check is a program. The “which of these places feels right for me” judgment is the AI.
The shelves versus the memory. Two layers, and the difference matters. The shelves are the plain text files, that’s the real thing, the truth, the part I own. The memory layer, I call it the brain, is the librarian’s recall: a fast index of everything, living on a server, that powers the instant search and the cross-session memory. The key point: the memory is rebuildable. If it ever vanished, the shelves would still be standing, untouched. I never depend on the clever part. I depend on the plain files.
Plain text means it outlives any one AI. Because the whole thing is just text files and small programs, not welded to one company’s app, it isn’t locked to today’s AI. It runs on Claude right now. It would run just as well on a different AI tomorrow. The system is built to outlive any single tool, which is the real reason I sleep fine having put my life’s knowledge into it.
🔍 Go deeper: the plain text format is called markdown. It’s just text with light formatting, openable in any editor on any computer, readable in 50 years. No database, nothing proprietary.
What it unlocks
Here’s where it stops being a personal library and becomes leverage on my actual livelihood.
🛠️ My work is consulting. 8 years of it. All the craft, the playbooks, the hard-won judgment, used to live in my head and in a thousand scattered files. Now it’s becoming a distilled, queryable body of knowledge the AI can draw on. So when I take on a problem, I’m not starting from a blank page, I’m starting from my own accumulated best thinking, instantly accessible.
On top of that, the newest piece, only just taking shape, lets the system do real work on its own. I drop a task into an inbox, and the appropriate part of the system either does it, in the library, or drafts the solution and hands it back for me to approve. The librarian is starting to stop just filing and start doing. This is the frontier I’m building right now, and it’s the direction everything else has quietly been pointing toward.
Put those together: my distilled craft, plus a system that can answer as me and execute tasks for me, and the actual consulting work gets materially easier and faster. That’s the inversion reaching its conclusion. It started as an app I operated. It’s becoming the engine my work runs on.
Closing
So that’s it. Underneath, it’s just folders of text. But it’s the closest thing I have to a second mind: it remembers what I read, it connects what I think, it does real work for me, and it helps me understand myself. Nothing I feed it is lost anymore, not an article, not a trip, not a decade of work, not a hard-won thing about my own life.
It went from an app I operated to a system that operates for me. I wrote this so the people closest to me could actually see it, instead of it being a thing I quietly disappear into.
Appendix: under the hood
For the technically curious. None of this is needed to understand the system, it’s the machine room.
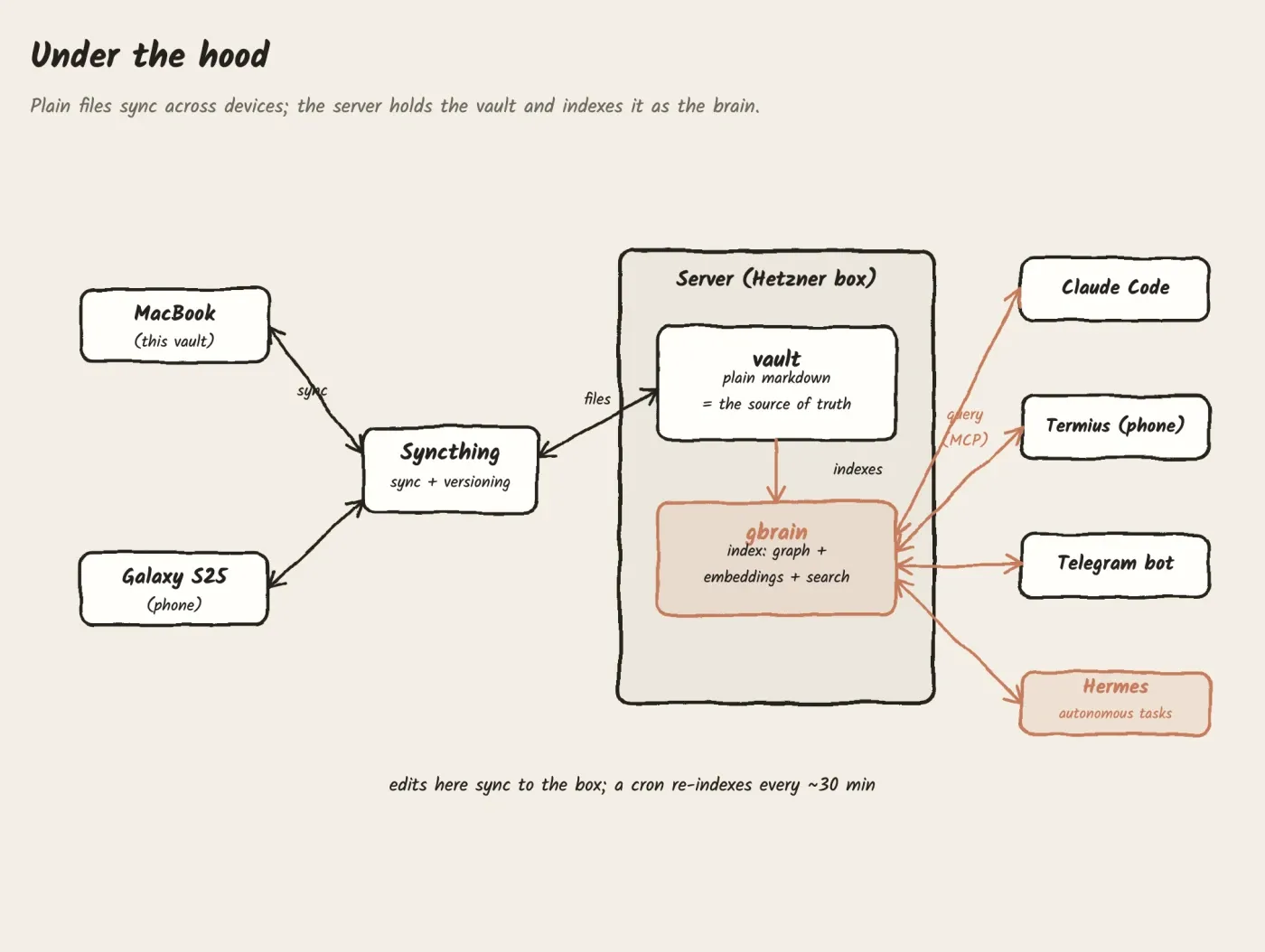
The substrate. Everything is plain markdown files in a folder structure (the “vault”). Markdown is the only persistence layer, there’s no application database holding the real content. Files are the source of truth: explicit, inspectable, portable, and version-controllable. Obsidian is used only as a viewer.
The skills. 14 custom skills package the recurring procedures: ingesting each content type (clip-article, clip-video, clip-podcast, clip-pdf, clip-book), compiling raw notes into wiki articles, the question-and-answer loop, content discovery and queue review, and an autonomous task worker. The operating philosophy is “thin harness, fat skills”: a small always-loaded set of instructions, with detailed procedures loaded only when invoked.
The 16 scripts (deterministic layer). Small Python and shell programs for the work that must be exact and repeatable: place_discovery.py (finds quality places by searching domain-specific “shibboleth” vocabulary and flagging statistical outliers against the local baseline), place_liveness.py (verifies a place is currently operating, catching closures and rebrands), youtube_transcript.py (transcript and metadata extraction), batch_extract.py (analyzes work sessions at scale), plus feed fetching, session capture, and sync utilities. This is the “machinery, not judgment” half of the design.
gbrain (the memory layer). A knowledge-graph and retrieval service running as a systemd service on a Hetzner ARM server. It indexes the whole vault into Postgres with pgvector for semantic (embedding-based) search, plus keyword search and a typed link graph. Around 600 pages are indexed. It’s exposed to the AI over an MCP endpoint, so any session can query the full corpus. A cron job re-indexes the vault roughly every 30 minutes, so vault edits propagate automatically, and it auto-updates and backs up daily. Critically, gbrain is a derived, rebuildable index. The markdown vault remains canonical, if gbrain disappeared the vault would be unaffected.
Sync and access. The vault syncs across the MacBook, a Galaxy S25, and the server via Syncthing, with 90-day file versioning. The brain is reachable from the phone over SSH (Termius) and via a Telegram bot gateway, so the full system is usable on the go.
Model-agnostic by construction. Because the substrate is plain text and small scripts rather than a proprietary app, the AI layer is swappable. It runs on Claude Code today and would run on another agent (for example Codex) with no change to the underlying knowledge.
Lineage. The current system is the second generation. The first, dwu-brain-tools, was a Next.js web app (90 commits, May 2025 to February 2026) with a multi-provider LLM abstraction, a ChromaDB vector store for RAG, a two-stage content discovery scorer, and audio transcription. Its patterns were carried forward, its app shell was discarded in favor of the markdown-first design.
Glossary
- Vault: the folder of markdown files that holds everything. The source of truth.
- The brain (gbrain): the server-side memory layer that indexes the vault for fast and semantic search and cross-session memory. Rebuildable.
- Compile: the AI synthesizing many raw notes into one coherent, cross-linked wiki article, and keeping it updated.
- Markdown: plain text with light formatting, openable anywhere, durable for decades.
- RAG: retrieval-augmented generation, fetching relevant notes from your own corpus and giving them to the AI so it answers from your knowledge, not just its training.
- MCP: the protocol that lets the AI query the brain as a live tool during a conversation.